

At a glance:
- Real estate’s document-centric nature historically led to fragmented, siloed datasets, but Property Intelligence now leverages this data for actionable insights and strategic decision-making.
- Intelligent Document Processing (IDP) acts as a critical catalyst, transitioning the industry from manual transcription to AI-powered data extraction for risk and opportunity management.
- As document volumes grow, IDP is the essential differentiator for real estate leaders, transforming complex silos into a fountain of deep, semantic property intelligence.
- The Bottleneck: Why legacy real estate data extraction methods fail property intelligence
- Benefits of AI-based real estate data extraction: From extraction to property intelligence
- How AI-based real estate data extraction works
- Key document types AI extracts for property intelligence
- Role of real estate intelligent document processing (IDP) platforms like Hitech i2i
- Future of AI-driven property intelligence
- Conclusion: The roadmap to the intelligent real estate enterprise
Over the years real estate has been a document centric industry. Right from the residential loan application to the final sale contract execution, every step is a fine blend of text, tables and signatures. However, till recent past this crucial data was ignored and hence it remained siloed and fragmented in form of scanned PDFs, physical property records, and complex appraisal reports.
Property Intelligence (PI) is the industry’s response to siloed and fragmented property datasets. Real estate data now fuels tasks like automated risk scoring, dynamic valuation, and proactive lease compliance. But for attaining PI at scale, it is critical to bridge the gap between raw documents and structured data.
Here Intelligent Document Processing (IDP) for real estate data plays the catalyst that enables Property Intelligence (PI). Automated data extraction is all set to transform manual data entry to proactive intelligence generation.
AI-based IDP is no longer a tool to improve operational efficiency; but is a foundational technology that unlocks scalable, accurate Property Intelligence. It is fundamentally changing how real estate companies manage risk and capitalize on market opportunities.
The bottleneck: Why legacy real estate data extraction methods fail property intelligence
Before AI-driven property intelligence can deliver reliable insights, real estate companies are confronted with data that is fragmented, inconsistent, and operationally expensive to manage.
These challenges manifest across three interrelated dimensions; poor data quality, excessive time consumption, and rising operational costs, and each of them compound the other.
Poor data quality: Fragmentation and inconsistency
Real estate data is collected from a fragmented ecosystem comprising of property records, title documents, leases, mortgage filings, appraisal reports, financial statements, and public registries.
These information sets arrive in a wide plethora of formats and levels of completeness, bringing in common quality issues such as:
- Inconsistent legal descriptions across deeds and titles
- Conflicting ownership records between county filings and lender documents
- Non-standard valuation metrics in appraisal narratives
- Variations in clause language across leases and sale contracts
These inconsistencies can prove fatal for valuation and fraud detection models as they introduce noise that skews price signals, masks risk indicators, and weakens predictive accuracy. Without clean, normalized, machine-readable inputs, even the most sophisticated analytic models produce unreliable outcomes.
Time Consumed: Manual processing bottlenecks
Manual abstraction remains a major operational drag in property intelligence workflows. Processing scanned PDFs, handwritten notes, legacy forms, and image-based filings requires intensive human review.
Analysts spend significant time reviewing long-form appraisals, cross-verifying lease clauses, and rekeying data into downstream systems.
- Underwriting cycles slow due to document-heavy reviews
- Deal teams wait on incomplete or conflicting data
- Compliance checks extend transaction timelines
In fast-moving acquisition environments, delays caused by manual document review often result in missed opportunities or rushed, suboptimal decisions. For real estate data aggregators and analytics providers, delayed data ingestion leads to stale insights in volatile markets where pricing and risk conditions shift rapidly.
Cost incurred: Scaling inefficiencies
Manual data processing is expensive and does not scale linearly. As document volumes increase, so do labor costs, error remediation efforts, and quality assurance overhead.
- Repeated data abstraction adds recurring expenses
- Rework caused by data errors inflates operational costs
- Compliance failures trigger penalties and remediation efforts
As portfolios expand, the cost of managing document-driven workflows increases non-linearly. Without clean, normalized, machine-readable data, property intelligence systems cannot scale efficiently or reliably.
To enable high-fidelity property intelligence, organizations must replace document-centric workflows with AI-driven, standardized data pipelines.
Clean, normalized, and continuously updated data is no longer a technical preference, instead it is a commercial necessity for competitive property intelligence offerings. They are foundational to accurate, scalable, and cost-effective property intelligence.
Benefits of AI-based real estate data extraction: From extraction to property intelligence
Once the data challenges of poor quality, excessive processing time, and rising operational costs are addressed; property intelligence systems finally perform at their intended level.
AI-based real estate data extraction provides that solution by replacing manual, document-centric workflows with scalable, intelligence-driven pipelines.
Solving poor data quality
AI based data extraction tool leverages domain-trained OCR, NLP, and entity-resolution models to standardize data across diverse real estate documents.
Instead of inconsistent, analyst-dependent abstractions, real estate data aggregators can get their hands on validated, normalized, and machine-readable property datasets.
Key data quality improvements include:
- Standardized ownership and legal entities across deeds and titles
- Consistent valuation parameters extracted from appraisal narratives
- Reconciled lease terms aligned with financial statements
For valuation model and fraud analysis companies, this consistency directly improves model precision by eliminating noise or conflicting input, critical for automated valuation models (AVMs) and anomaly detection systems.
Eliminating time bottlenecks
AI-driven extraction reduces manual abstraction by 70–90%, enabling thousands of documents to be processed simultaneously rather than sequentially.
This accelerates:
- Underwriting and acquisition cycles
- Title verification and lien clearance
- Compliance and onboarding reviews
- Near-real-time updates to valuation and risk models
For real estate data aggregators, faster ingestion means fresher datasets delivered to clients. For competitive acquisition environments, near real-time document intelligence enables quicker, more confident pricing and bid decisions.
Reducing operational costs at scale
Manual processing scales linearly with volume; AI scales exponentially. Automated extraction minimizes rework, repeat reviews, and downstream corrections major hidden cost drivers in traditional workflows.
Cost advantages include:
- Scale institutional-grade portfolios without proportional cost increase
- Process hundreds of millions of documents with consistent intelligence output
- Reduced QA cycles through automated validation
- Fewer compliance-driven reprocessing events
In effect, AI-based real estate data extraction transforms property intelligence from a cost center into a scalable, revenue-enabling asset.
By delivering cleaner data, faster insights, and lower unit economics, it enables institutional-grade valuation accuracy, risk modeling, and portfolio expansion at a speed and scale manual processes can no longer match.
How AI-based real estate data extraction works
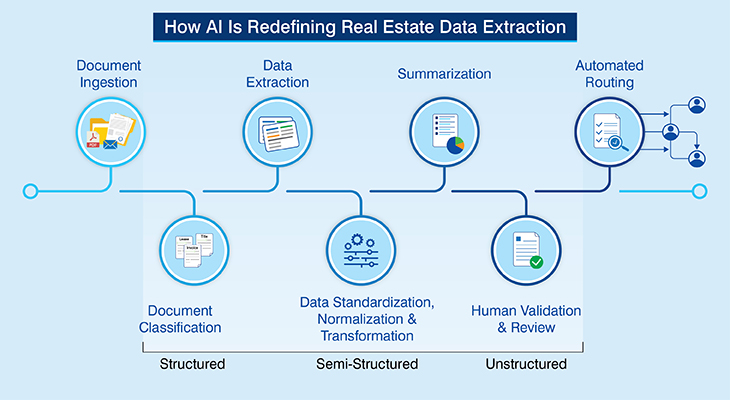
AI-based real estate data extraction follows a structured pipeline that converts raw property documents into standardized, decision-ready intelligence through automation, domain-trained models, and human oversight.
Property document ingestion
Property document ingestion is the entry point of the AI-based data extraction pipeline.
At this stage, real estate documents are collected from multiple sources such as email inboxes, document management systems, loan origination platforms, property management software, APIs, and shared drives.
The system supports a wide range of formats, including scanned PDFs, native PDFs, images, and digitally generated files.
Examples:
- A bulk upload of scanned lease agreements from a property acquisition
- Capturing mortgage documents received via lender portals
- Appraisal reports uploaded as PDFs by valuation teams
- Property records pulled directly from county assessor databases
- Uploading mobile-captured images of handwritten inspection notes
The ingestion layer ensures documents are securely captured, indexed, and queued for processing without manual intervention.
Property document classification
Once ingested, AI models automatically classify documents based on layout, language patterns, and contextual cues. This step determines document type and assigns the appropriate extraction logic and workflow.
Examples:
- Identifying a 100-page legal file as a Sale Contract versus a Title Document
- Classifying multi-form loan packages into residential loan applications, disclosures, and credit reports
- Separating appraisal reports from financial statements within loan files
- Distinguishing property management agreements from standard lease agreements
Property data extraction
In this stage, AI engines use OCR, handwriting recognition, NLP, and computer vision to extract relevant data fields from structured, semi-structured, and unstructured content.
The automated data extraction is context-aware, enabling the system to understand relationships between fields rather than relying solely on fixed templates.
Examples:
- Extracting rent amounts, escalation clauses, lease terms, and CAM charges from lease agreements
- Capturing loan amount, interest rate, borrower details, and collateral data from mortgage documents
- Pulling valuation figures, comparables, and adjustments from appraisal reports
- Extracting legal descriptions and ownership history from title documents
Property data standardization, normalization and transformation
After extraction, the raw data is cleaned, standardized, and transformed into consistent, system-ready formats. This ensures uniformity across documents originating from different regions, lenders, or property types.
Examples:
- Converting multiple date formats into a standardized ISO format
- Normalizing rent values across monthly, quarterly, and annual representations
- Standardizing address formats and parcel identifiers across county records
- Transforming extracted data into structured JSON or database-ready schemas for downstream systems
This step is essential for analytics, reporting, and integration with property intelligence platforms.
Human supervised AI
Human-in-the-loop oversight ensures accuracy, especially for low-confidence extractions or high-risk documents. Reviewers validate, correct, and approve AI outputs, and their feedback is used to continuously retrain and improve model performance.
Examples:
- Reviewing ambiguous ownership details in title records
- Verifying handwritten values in scanned mortgage documents
- Approving AI-extracted clauses from complex lease agreements
This supervised approach balances automation with control, ensuring enterprise-grade accuracy and compliance.
Together, these stages create a resilient AI-powered framework that transforms complex real estate documents into accurate, standardized, and actionable property intelligence at scale.
Key document types AI extracts for property intelligence
Accurate property intelligence depends on extracting legally critical data buried across diverse real estate documents.
AI-driven extraction ensures ownership, lien priority, encumbrances, and foreclosure signals are captured consistently, reducing risk, improving due diligence accuracy, and enabling faster, data-backed decisions across the entire property lifecycle.
The following table highlights key real estate document categories from which AI systematically extracts structured intelligence to support ownership verification, risk assessment, compliance validation, and valuation workflows.
| Category | Document Types | Common AI-Extracted Fields |
|---|---|---|
| Deeds / Conveyance Documents |
|
|
| Mortgage / Security Documents |
|
|
| Lien & Encumbrance Documents |
|
|
| Foreclosure / Default Documents |
|
|
By extracting and correlating intelligence across these documents, AI delivers a unified, risk-aware property view that supports confident valuation, underwriting precision, and legally sound real estate decisions.
Role of real estate intelligent document processing (IDP) platforms like Hitech i2i
Modern property intelligence needs replacing fragmented manual workflows with AI-driven intelligent data extraction process designed and deployed for complex real estate ecosystems.
Hitech i2i, the unique AI-backed intelligent document processing platform, serves as a backbone for real estate companies.
Purpose-built extraction for real estate
At its core, Hitech i2i is a purpose built data extraction solution for real estate industry’s unique vocabulary. We ensure that the entity models are optimized with property-specific terminology, i.e., for identifying “triple-net” clauses or “lien” details with granular precision we do not use generic OCR. Instead, our solution is pre-trained on high-density documents like complex leases, deeds, titles, and mortgage files.
End-to-End automation
Our IDP solution is a seamless orchestration of document activities right from ingestion and extraction to validation, summarizing and final routing, demonstrating the true meaning of end-to-end automation. We eliminate the need of manual intervention in common workflows.
Multi-Format Mastery
Our real estate data extraction solution can effortlessly handle structured forms, semi-structured financials, unstructured narratives, and even handwritten annotations found on historical records, showcasing its capabilities across the spectrum.
Quality, Accuracy & Validation Controls
We have incorporated sophisticated quality and validation controls in our intelligent document processing platform to ensure institutional-grade reliability. It is an amalgamation of cross-document reconciliation like matching lease commencement dates with incoming financial statements. Our platform also has human-in-the-loop (HITL) review option for edge cases.
Deployment Flexibility
The most important benefit to you is that our platform comes with deployment flexibility. Our platform integrates with your existing valuation tools, underwriting engines, and ERP systems through an API-first approach or a hybrid cloud/on-premise installation. We ensure that all the extracted intelligence is made immediately accessible where it is needed the most.
Our automated data extraction solution bridges the gap between raw document in silos and actionable data, empowering you, as a real estate company, to scale operations without increasing your administrative overhead.
Future of AI-driven property intelligence
The next frontier of property intelligence lies in shifting from isolated document extraction to comprehensive, autonomous reasoning across entire asset lifecycles and global portfolios.
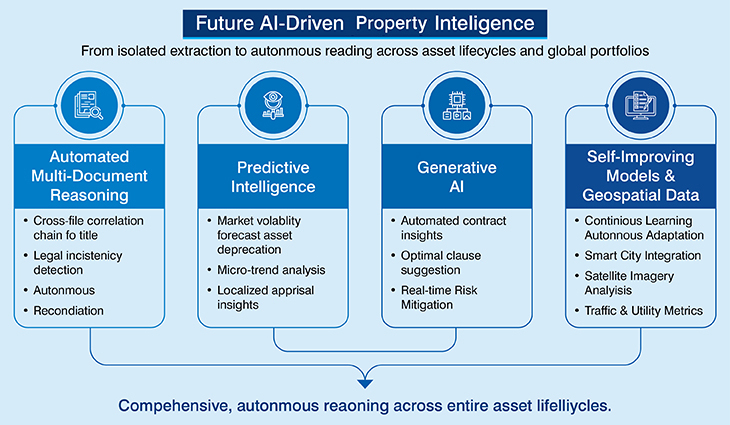
- Automated multi-document reasoning: A pivotal advancement in this space is automated multi-document reasoning. While current systems extract data from single files, future platforms will perform cross-file correlation automatically reconciliating a chain of title with historical zoning records and current mortgage liens to flag complex legal inconsistencies without human prompting.
- Predictive intelligence: This aggregated, document-derived data will fuel predictive intelligence, allowing firms to forecast market volatility or asset depreciation by analyzing micro-trends buried within thousands of localized appraisal reports and financial statements.
- Generative AI: We are also seeing the emergence of Generative AI for more than just summarization; it is moving toward automated contract drafting and negotiation insights. By analyzing historical successful negotiations, AI can suggest optimal clause language to mitigate risk in real-time.
- Self-improving models: These systems will be powered by self-improving models that exhibit continuous learning, autonomously adapting to new document types or changing regulatory formats without requiring manual retraining.
- Smart city and geospatial datasets: Finally, the convergence of document intelligence with smart city and geospatial datasets will redefine valuation. By integrating internal document data with external satellite imagery, traffic patterns, and utility consumption metrics, property intelligence will move beyond the four walls of a building.
This holistic view will provide an unprecedented level of transparency, transforming real estate from a traditional “gut-feeling” industry into a high-precision, data-driven science.
Conclusion: The roadmap to the intelligent real estate enterprise
The real estate industry has reached a tipping point. As the volume and complexity of document-based data continue to grow, the reliance on manual processing is no longer sustainable. AI-based real estate data extraction is the non-negotiable prerequisite for any firm seeking to achieve scale and strategic property intelligence.
The IDP solution moves the needle from simple digitization to a deep, semantic understanding of complex legal and financial documents. In the coming years, the primary competitive differentiator for leading players will not just be their assets, but the speed, accuracy, and intelligence of their underlying data ingestion architecture.
By embracing AI-powered IDP, real estate firms can finally turn their document silos into a fountain of actionable intelligence.
← Back to Blog