

At a glance:
- Real estate documents are a pile up from titles, appraisals, and mortgages, each with their own unusual formats and jargons.
- Intelligent automation flips this chaos into clean, actionable data pipelines through normalization and schema mapping.
- It operationalizes the data reliably, fuels faster decisions, fewer errors, enabling a ready to use accurate and uniform property data repository.
- Why real estate data needs normalization & schema mapping
- Understanding data normalization in real estate
- Understanding schema mapping in real estate data pipelines
- Intelligent document automation in real estate: The game-changer
- How Hitech i2i’s IDP engine automates normalization & schema mapping
- Real-world use cases: Intelligent document automation at work
- Looking ahead: Knowledge graphs and data lakes
- Conclusion: Data normalization as the foundation of trust
Data is the primary currency for real estate industry. However, for most of the players this currency is locked in “non-convertible” formats. While the industry is drowning in data rich mortgages, appraisals, and title documents, it remains information poor. Lack of digitization is not the culprit, but lack of harmonization is.
Real estate data aggregators often focus on “extraction” phase of Intelligent Document Processing (IDP). They celebrate when an OCR or ICR engine accurately identifies a “Commencement date” on a property agreement.
But this is only the first step. The real challenge is how to reap the “hidden advantage” of intelligent automation; Data Normalization and Schema mapping (N&SM). These two are mission critical activities that transform raw, extracted noise into decision-ready, harmonized structures. And AI-based document classification for accurate data extraction is the key to success.
Why real estate data needs normalization & schema mapping
Property data is a mess and includes all structured forms like housing loan applications, semi-structured PDFs of sales contracts, and unstructured scans of handwritten notes.
Real estate data platforms, Real estate data aggregators, title search companies, valuation model companies, fraud analysis companies, etc. spend hours reconciling “Unit 2-B” and “Apt 2B”, or mismatched property IDs across systems. Lack of normalization results in tanked analytics, compliance checks, and AI models built on weak foundations. Here are two lessons that the real estate industry learnt a very hard way.
- Zillow suffered $569 million loss and a 25% workforce reduction due to a manual error which overestimated home values, resulting in unsustainable purchases and a significant financial write-down.
- Lack of data normalization and schema mapping led a county tax assessor’s office to miss out on assessing 25,000 acres of oil fields and lost $12 million in annual revenue.
Traditional OCR and ICR systems extract text but lack contextual understanding. Capturing non-tabular data and handwritten notes e.g., amendments in sale contracts.
At the same time, taking the template-based automation approach fails as and when formats of high-stakes documents like property management agreements, title documents, residential loan applications change. This is exactly where AI-powered data extraction steps into the picture.
Document diversity happily make the rule based approach struggle and collapse. Even two agreements from different regions or years will have distinct layouts, terminology, and field names for the same concept e.g., “Tenant Name” vs. “Lessee”.
Real estate data automation demands a system that can interpret intent, structure, and relationships and not just characters on a property document. Normalization plus schema mapping, together, ensure data interoperability and enable unified views.
Understanding data normalization in real estate
So now that we have seen what the impact of lack of normalization and schema mapping is, before we move further, let’s check out on what data normalization is and why it is so critical for real estate data.
| Topic | Key Concepts | Business Impact |
|---|---|---|
| What is Data Normalization |
|
|
| Why Real Estate Needs Normalization |
|
|
| Inconsistent Terminology & Formats |
|
|
The cost of poor data normalization
The cost of poor data normalization is quantifiable. It starts with broken Extract, Transform, Load (ETL) workflows and failed ingestion which ultimately halts the operations.
This leads to misaligned appraisal comps, inaccurate Automated Valuation Model (AVM) results, and flawed risk scoring. Manual reconciliation cycles are endless, consumes massive operational bandwidth to make the data usable, which makes it non-feasible.
Industry standards for normalization
To achieve true interoperability, normalization must align with established industry formats. Intelligent Document Processing (IDP) is engineered to output data compliant with:
- PRIA (Property Records Industry Association): Essential for land records and document recording. PRIA standards ensure that extracted data from deeds, mortgages, and liens is formatted correctly for government recorders.
- MISMO (Mortgage Industry Standards Maintenance Organization): The standard for the residential and commercial mortgage industry. Normalizing data to MISMO formats is critical during the “Mortgage Document” processing phase to ensure seamless communication between lenders, underwriters, and secondary market investors.
- RESO (Real Estate Standards Organization): sets the standards for structuring and exchanging real estate data, converting fragmented Multiple Listing Service (MLS) data into a “universal language”.
- ALTA (American Land Title Association): The minimum standard requirements for land title surveys; it ensure that surveying data is consistent across different practitioners and that title companies can insure against risks.
Normalization resolves extreme semantic fragmentation. The cost of poor normalization is quantifiable: it leads to broken ETL workflows, misaligned appraisal comps, and inaccurate Automated Valuation Model (AVM) results. Without automated normalization, firms are forced into endless manual reconciliation cycles.
Understanding schema mapping in real estate data pipelines
So now that the data is normalized if you think that the task is over, you are mistaken. Normalization is about the value of data, whereas schema mapping is about its destination.
What is schema mapping?
Schema mapping is the process of aligning disparate data sources to unique data models and defines relationships, hierarchies, and business rules.
For e.g., it defines how extracted field like Lsr_Nme in a legacy lease scan maps to Property.RentalAgreement.Lessor_Name in your ERP or CRM.
Why schema mapping is complex in real estate
In real estate industry, non-standard formats of document like legacy PDFs and handwritten forms makes schema mapping notoriously complex. Field definitions vary hugely; depending on the municipality or management company “termination clause” can be a simple date in one schema but a multi-conditional nested object in another schema.
Said that, we cannot deny the fact that new and frequent change in compliance requirements or region-specific additions make static mapping logic obsolete and schema drift in the real estate industry.
How failed schema mapping affects operations
The impact that failed schema mapping leaves is catastrophic. The system is unable to identify the document’s intent which breaks the workflow routing logic. You see a sudden spike in errors in your ERP and CRM systems, resulting in total loss of data lineage.
Unmapped or inconsistent attributes makes the “intelligent” part of the process fail, resulting in halted decision automation and high-speed pipelines are pushed back into manual bottlenecks.
Aligning with RESO and transactional schemas
In the listing and brokerage world, the RESO (Real Estate Standards Organization) Data Dictionary and Web API are the benchmarks. When processing “Sale Contracts” or “Property Records,” our IDP maps extracted attributes directly to RESO-compliant structures.
This ensures that property characteristics (e.g., BedroomsTotal, LotSizeSquareFeet) are immediately ready for MLS ingestion or listing syndication.
When to use which format
- Transactional/Legal: Use PRIA and MISMO mapping when the data is moving toward official recording, title insurance, or loan securitization. These schemas prioritize legal precision and audit trails.
- Marketing/Valuation: Use RESO mapping when the data is intended for marketplace platforms, CRM integration, or comparative market analysis (CMA). These schemas prioritize discoverability and searchability.
When schema mapping fails, workflow routing logic breaks and CRM/ERP ingestion errors spike. Most importantly, it stalls decision automation; if the attributes are unmapped, the “intelligent” part of the process fails.
Intelligent document automation in real estate: The game-changer
Intelligent Document Processing (IDP) has fundamentally redefined how real estate organizations handle document-heavy, data-intensive workflows.
It allows the system to handle the inherent variability of real estate formats like appraisal reports, title documents, mortgage files and many more; without requiring template specific retraining. This makes it resilient to format drift and jurisdictional variation.
How intelligent document processing (IDP) goes beyond OCR
Intelligent Document Processing (IDP) can be considered to be a paradigm shift from traditional Optical Character Recognition (OCR) approach.
Legacy OCR was limited to transcribing pixels into strings, however, IDP blends Natural Language Processing (NLP), computer vision, and layout detection to classify understand documents contextually, and not just visually.
Normalization as a native output of IDP
A key differentiator of IDP is that data normalization is a native output, not a post-processing step.
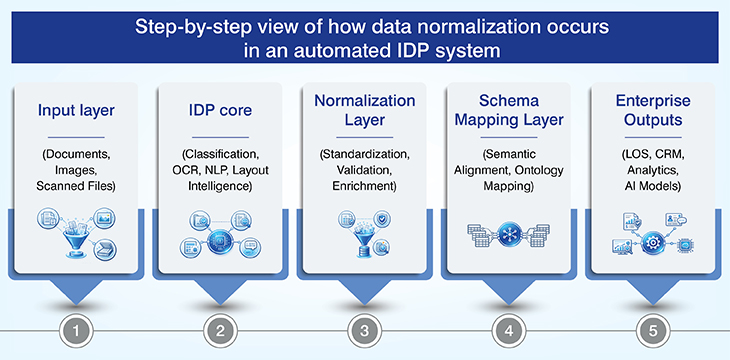
Advantages of IDP powered data normalization
IDP powered data normalization gives sure shot results in form of clean, deduplicated datasets always ready for schema alignment and system ingestion.
And not only this, but it also enhances the analytical reliability of the datasets, eliminates data inconsistencies and streamlines integration of accurate data with MLS systems, CRMs, and valuation engines.
Normalization of property addresses and title information during bulk property onboarding are classic example of how beneficial it is to use IDP powered data normalization.
Schema mapping powered by machine learning
Taking ahead the normalized data, schema mapping powered by machine learning converts datasets into unified, ontology-driven structures.
Instead of using rigid, manual scripts, the machine learning models detect source schemas and identify different fields using probabilistic matching and confidence scores.
This accelerates data interoperability, aligns datasets for AI and analytics pipelines, and reduces reliance on fragile custom data engineering scripts.
How Hitech i2i’s IDP engine automates normalization & schema mapping
Our Intelligent Document Processing (IDP) solution is purpose-built for real estate document automation. Trained on a wide spectrum of real estate documents, it can handle structured, semi-structured, and unstructured data with equal efficiency. It is an end-to-end pipeline that integrates capture, extraction, and normalization & schema mapping into a single workflow.
Omni-channel capture and intelligent data extraction
The source document can be a high-resolution PDF of a mortgage document or a mobile-captured photo of a handwritten amendment; our OCR/ICR engines capture it reliably. However, the game here is of intelligent data extraction.
We have trained our models using millions of real estate documents, to not to just “see” text but “understand” the information in a Property Management Agreement or a Residential Loan Application.
Seamless transformation
Normalization and schema mapping are an integral part to the architecture of our IDP solution. This enables us to transform the data in near real time basis. We know your business needs and hence deliver structured datasets instead of raw CSV of text.
So, now if your legal department needs dates in DD-MMM-YYYY whereas your accounts division requires it in MM-DD-YYYY, our tool is equipped with dynamic schema transformation to handle both the requirement.
Real-world use cases: Intelligent document automation at work
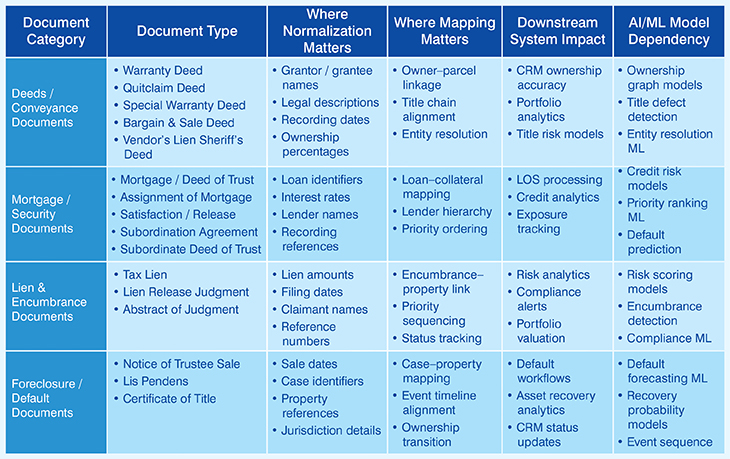
This table outlines the processing requirements for key real estate documents, including deeds, mortgages, liens, and foreclosure records. It specifies necessary data normalization and schema mapping points to ensure accuracy.
Finally, it details the resulting impact on critical downstream systems like LOS, CRM platforms, and risk analytics engines.
Looking ahead: Knowledge graphs and data lakes
As we look to the future, data normalization and schema mapping will be the foundation for real estate knowledge graphs.
By having perfectly mapped and normalized data, enterprises can begin to infer non-obvious relationships identifying hidden risks across a portfolio or discovering new investment opportunities by linking disparate property records, tax liens, and appraisal trends.
Conclusion: Data normalization as the foundation of trust
Intelligent Document Processing is often marketed as a way to “read” documents. But for the technical stakeholder, “reading” is not enough. The goal is utility.
Without robust, automated data normalization and schema mapping, your automation strategy is just a faster way to create a mess. Hitech i2i differentiates itself by making these “hidden” layers the core of our solution. We don’t just extract data; we deliver the infrastructure for property data excellence.
← Back to Blog