

99%
field-level accuracy
24 Hr
turnaround time
1,000+
USA counties supported
60-70%
operational cost reduction
Real estate documents are legally complex, semi-structured, and highly inconsistent across counties, jurisdictions, and time periods. They frequently contain tables, annotations, handwritten notes, and legacy scan formats, making generic OCR and rule-based extraction unreliable at scale.
Hitech i2i performs instrument-level data extraction as part of an end-to-end intelligent document processing pipeline purpose-built for real estate.

We leverage AI-powered algorithms to quickly and accurately extract data from all types of real estate documents, reducing manual effort and streamlining workflows.
Our smart data extraction uses AI to automatically identify, capture, and organize information from property documents, saving time and reducing errors.
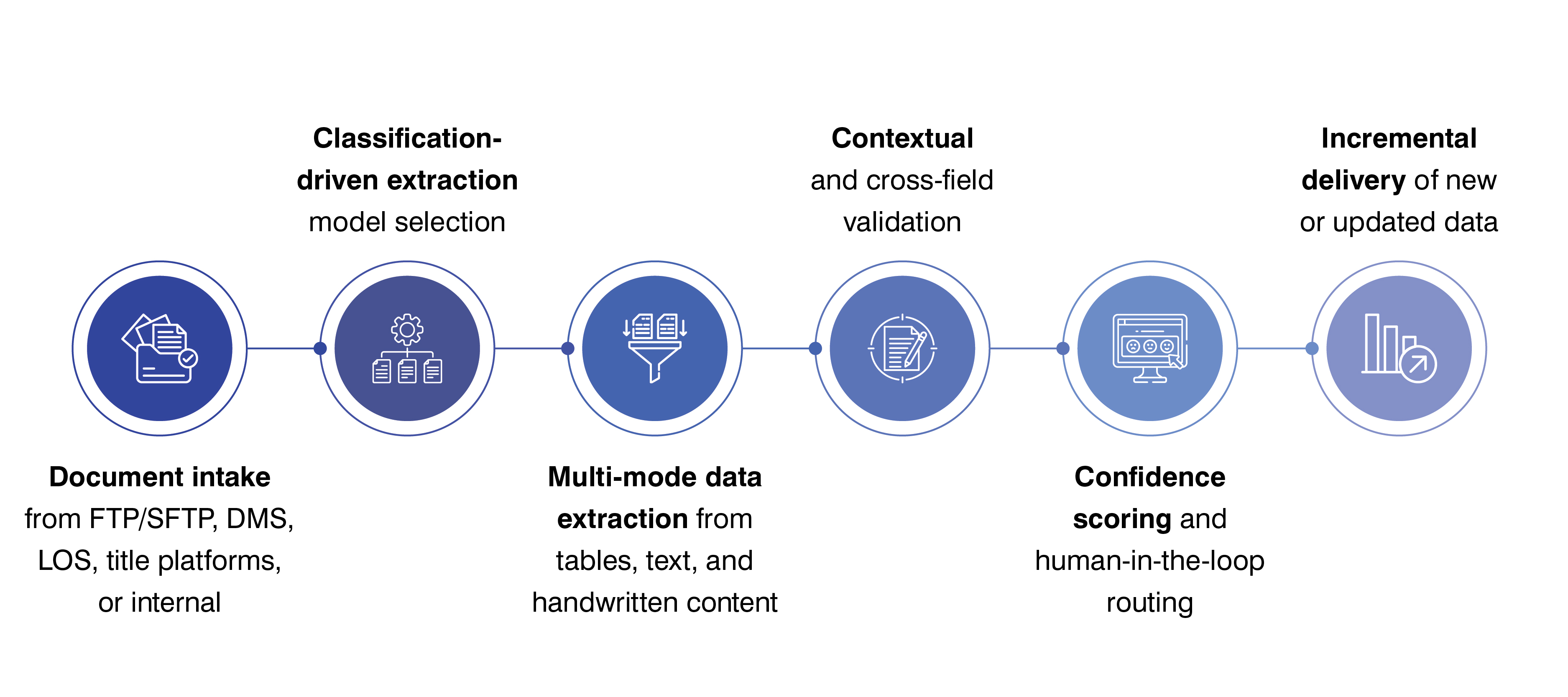
We extract key information from a wide range of real estate documents, including contracts, leases, property details, and financial records efficiently.
Address, Parcel/APN, Legal Description
Grantor, Grantee, Borrower, Lender
Instrument Number, Recording Date, Transaction Date, Consideration
Lien Position, Mortgage Type, Assignments, Releases
Hitech i2i developed an AI-powered document processing solution to digitize and extract data from historical city directories to reconstruct property ownership timelines and enrich real estate intelligence platforms. These documents were often poorly scanned, irregular tabular layouts, and difficult to read documents. Computer vision, automated column detection, and human-in-the-loop validation enabled accurate, scalable extraction of structured archival data.
80%
reduction in manual work99%
scan quality detection accuracyExample: If a mortgage document contains a table listing loan amount, interest rate, maturity date, and payment terms, Hitech i2i correctly identifies the table structure and maps each cell to the appropriate data field rather than flattening it into unstructured text as generic OCR tools do.
Example: Handwritten release notations, margin notes indicating partial satisfaction, or handwritten corrections on older deeds can be detected and extracted as contextual signals rather than ignored.
Example: County deed books scanned from microfilm or decades-old paper records often unreadable to standard OCR can still be processed accurately using Hitech i2i’s preprocessing and real estate trained extraction models.
Example: A warranty deed from Texas and a grant deed from California may look structurally different, but Hitech i2i extracts the same logical fields (grantor, grantee, legal description, recording date) in a consistent schema.
Example: One data platform may extract 20+ attributes for analytics, while another may extract only ownership and transaction dates. Hitech i2i supports both without re-engineering the pipeline.
Examples include: Hitech i2i’s intelligent data extraction can determine active versus inactive lien status by analysing mortgage and release documents, compute an effective ownership date from multiple recorded instruments, and create portfolio-ready indicators such as ‘first-lien only’ or ‘open mortgage present.’ All these calculated fields are delivered seamlessly alongside the extracted data, providing a complete, actionable view for real estate portfolios.
Example: A title data platform and an investor analytics platform can use the same extraction pipeline but apply different calculated rules tailored to their business models.
Example: If borrower name and loan amount are extracted with high confidence, they flow automatically. If a handwritten annotation introduces ambiguity, that specific field not the entire document is flagged for review.
Example: If only 5,000 new or updated records are processed today, only those changes are delivered avoiding full dataset refreshes and reducing downstream processing load.
See Hitech i2i Extract Your Property Documents – Free, No Commitment
Share a sample document and receive structured, field-level output within 48 hours.
Book a 15-Min DemoSOC 2-ready | GDPR-compliant | No contract required | Your data stays secure | Results in 48 hrs