

At a glance:
- Generic IDP tools plateau at 70-80% field-level accuracy on complex variable documents, the same category as county property records.
- County property records span 3,000+ U.S. jurisdictions with no unified data standard. Instrument names, field positions, and formats vary by county, state, and recording era.
- eRecording covers 88% of the U.S. population. The remaining 12% of jurisdictions still require scan-based extraction from microfilm and hand-indexed deed books.
- Domain-trained extraction is pre-trained on real estate instruments across 1,000+ county formats, accounting for all naming, layout, and recording-era variability above.
- The result for your pipeline is 90%+ straight-through processing, 99%+ field-level accuracy with HITL routing, and 60-70% lower processing costs versus generic IDP.
- What Is OCR for County Property Records and What Determines Field-Level Accuracy?
- Field-Level Accuracy: Generic IDP vs Domain-Trained on Property Documents
- Why Generic OCR Tools Fail on County Property Records: 3 Structural Layers
- The Solution: What Domain-Trained OCR for County Property Records Does Differently
- Efficiency Gains: What the Field-Level Accuracy Gap Costs in Practice
- Best Practices: 4 Steps for Data Platforms Processing County Property Records at Scale
- Future Outlook: Where OCR for County Property Records Is Heading
- How Hitech i2i Addresses Field-Level Accuracy Across 3,000+ County Property Record Formats
- Conclusion
- Frequently Asked Questions About OCR for County Property Records
- Methodology Note
If your platform aggregates county property records at scale, you have probably already seen this failure pattern. Field-level accuracy looks acceptable for weeks. Then a client flags a broken ownership chain, or a lender reports phantom encumbrances, and an internal audit reveals the IDP pipeline was never trained on what county records actually look like across jurisdictions.
County property records are among the most variable document categories in any extraction pipeline. The same legal event, a lien filing, a deed transfer, a mortgage assignment arrives under different instrument names and in different field positions depending on the jurisdiction and recording era. Formats range from structured e-recorded XML to hand-indexed 1940s deed books.
This article maps three structural failure layers specific to OCR for county property records and explains what domain-trained extraction delivers when it is working correctly. For the broader causes behind these failures, see the property record fragmentation guide.
What Is OCR for County Property Records and What Determines Field-Level Accuracy?
OCR for county property records is the extraction of structured field data such as grantor name, instrument type, recording date, parcel identifier from scanned or e-recorded instruments across 3,000+ U.S. county jurisdictions.
Field-level accuracy depends on whether the extraction model was trained on the specific instrument vocabulary, field layout, and recording-era format of each county, not on scan quality alone. A model achieving high character accuracy on standard warranty deeds may produce unusable field output on a Texas materialman’s lien, a Louisiana act of sale, or a pre-1960 microfilm deed.
Field-Level Accuracy: Generic IDP vs Domain-Trained on Property Documents
Before mapping the failure layers, you need to ground the accuracy comparison in field-level data, not character recognition rates. Character accuracy is the metric generic IDP vendors lead with because it produces the highest numbers.
Field-level accuracy measures whether a complete data field such as grantor name, instrument type, APN, recording date, is extracted correctly in its entirety. A single misread character in an APN or instrument type code produces a field-level failure regardless of character accuracy. This is the metric that determines whether your extracted county property record data is usable without human review.
| Document Type | Generic IDP Field-Level Accuracy | Domain-Trained Field-Level Accuracy | Source |
|---|---|---|---|
| Simple structured documents (invoices, standard forms) | 90-96% | 97-99% | Lido.app, OCR Accuracy, May 2026 |
| Complex variable documents (multiple templates, variable layouts) | 70–80% | 90–95%+ | Nanonets, IDP Explained, 2025 |
| Variable-template property documents (multiple local authority formats) | 70–72% plateau | 96% after domain-specific routing | IDP Software, IDP Accuracy Reckoning, 2026 |
| Mortgage/financial docs (real practitioner pipeline, 6,000/month) | 70–72% plateau | 96% after domain-specific routing | IDP Software, IDP Accuracy Reckoning, 2026 |
| Handwritten / degraded historical records | 80–87% character-level; field-level lower | 95–99% with HITL routing | Extend.ai, 2025 |
| County property records (all formats combined) | Extrapolated from complex variable range: 70–85% | 99%+ field-level with HITL routing and county-specific training | Hitech i2i operational experience, 1,000+ counties – see Methodology |
County property records span every row of this table simultaneously. A single pipeline encounters structured e-recorded XML, complex variable county forms, local authority templates with no standard layout, and handwritten historical instruments, all within the same day’s processing volume. Generic IDP tools benchmarked on clean structured documents have no architecture for this range.
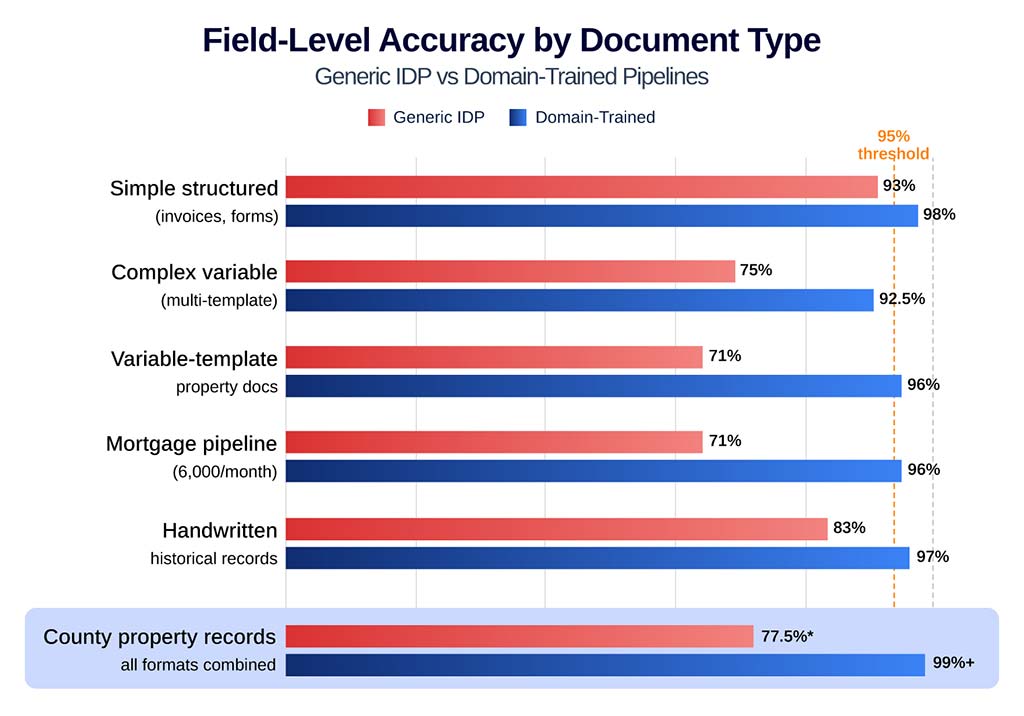
The accuracy gap widens with document complexity
- Simple structured documents: 4-6 point gap, manageable with any IDP tool
- Variable-template property documents: 25 point gap, production-critical
- County property records span every category, composite scores mask this reality
Why Generic OCR Tools Fail on County Property Records: 3 Structural Layers
Property record fragmentation operates at three distinct layers. Generic IDP tools typically fail at all three in different ways, with different downstream consequences. Understanding U.S. property record types across their full instrument taxonomy is the foundation for understanding where extraction breaks.
No unified data standard exists across the title industry unlike mortgages, real estate, and appraisals where standards are commonplace. For your extraction pipeline, every county is effectively its own document format.
Layer 1: Instrument Naming Variation Across County Property Records
The same legal event uses different instrument names across states, and sometimes across counties within the same state:
- Materialman’s lien in Texas is the equivalent of mechanic’s lien in most other states.
- Sheriff’s Deed (most states) vs Commissioner’s Deed (California) vs Referee’s Deed (New York) for the same court-ordered sale.
- Florida judicial foreclosures produce entirely different instrument types than non-judicial foreclosures in California.
- Louisiana uses acts of sale and acts of mortgage in place of common-law deeds and mortgage instruments.
A generic OCR tool encountering a Louisiana act of sale does not return an error. It classifies the instrument into the nearest common-law equivalent typically a warranty deed and passes it to output. The extraction appears to succeed. The county property record is structurally wrong. When the error is discovered, it is typically by a client, the most costly possible point of detection.
Practitioner Scenario 1: Louisiana civil-law misclassification (Q2 2024)
In Q2 2024, a national property data aggregator expanding from 38 states to all 50 added Louisiana coverage using extraction models built for common-law states. Louisiana is a civil-law jurisdiction with 64 parish offices, not county recorders.
The pipeline silently misclassified every act of sale, act of mortgage, and act of cancellation into common-law equivalents. Discovery came three months later via a client complaint. Remediation required rebuilding Louisiana as a separate classification module, a six-week engineering effort that was entirely avoidable.
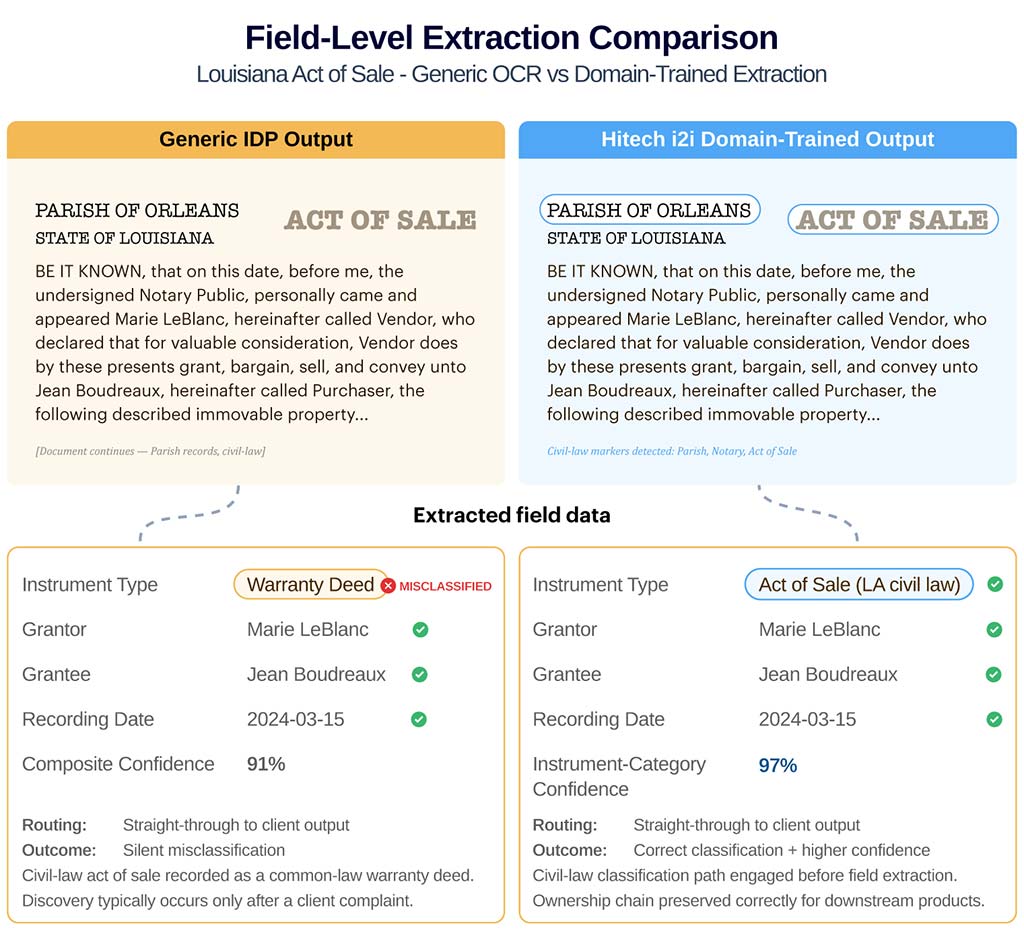
Why the comparison matters
The composite confidence score (91%) does not reflect the instrument-category error. Generic IDP returns “high confidence” while structurally misclassifying the document.
Document text redacted/anonymised. Output values illustrative.Research from the 2025 ACM Conference on Computing and Sustainable Societies confirms that handwriting recognition is particularly challenging for OCR models and typically requires specialized training datasets. This applies directly to historical county deed books and hand-indexed grantor-grantee records.
Layer 2: Format and Encoding Variation in County Property Record Processing
E-recorded documents arrive as structured digital files with labelled fields. Scanned records from the 1970s through 1990s require OCR to locate the same fields wherever that county’s printed form placed them, which varies by:
- County: a grantor name in the top-left corner of a 1985 Cook County deed appears in a completely different position on a 1985 Harris County deed.
- Decade: counties changed printed form vendors multiple times across recording eras.
- Recording method: structured XML, TIFF scan, microfilm, and hand-indexed deed books each require fundamentally different extraction logic.
eRecording covers approximately 88% of the U.S. population. The remaining 12% still record on paper or in formats requiring scan-based extraction. For a platform covering 1,000+ counties, that 12% represents hundreds of county format variations that generic IDP cannot handle without county-specific training.

The format problem compounds with property age. A pre-1950 property triggers extraction from deed books, microfilm, and hand-indexed grantor-grantee records. Generic IDP tools treat these as high-noise images and frequently return partial or garbled field values.
An intelligent OCR agent deployed to digitize decades of handwritten county deed records achieved 95% accuracy, but only after implementing purpose-built pre-processing pipelines specific to that county’s document characteristics. Generic OCR on the same records produced fragmented output requiring extensive manual correction.
Layer 3: Indexing and Cross-Reference Variation Across 3,000+ County Jurisdictions
The same county property record appears under different APN formats, different grantor-grantee spelling conventions, and different cross-reference structures depending on the county’s land records management system (LRMS):
- Cook County, Illinois uses proprietary instrument type codes that differ from downstate Illinois conventions.
- When Cook County upgraded its LRMS, those codes changed platforms without format-change monitoring saw release instruments stop being recognized, producing phantom encumbrances across hundreds of files.
- Grantor name indexing conventions vary between “Last, First” and “First Last” formats at the county level, breaking cross-reference logic built on name-matching.
Practitioner Scenario 2: Coverage audit reveals untested lien taxonomy (Q3 2024)
In Q3 2024, a mid-sized property data aggregator covering 620 counties conducted a coverage audit after a client reported systematic lien errors. The audit found 180 counties, 29% of their coverage had never had their lien instrument taxonomy specifically validated.
A county listed as in coverage for deed recording had a significant failure rate on mechanic’s lien instruments that had never been tested. Re-classifying counties into tiers and validating the top 40 within 90 days produced a measurable reduction in client-visible lien errors.
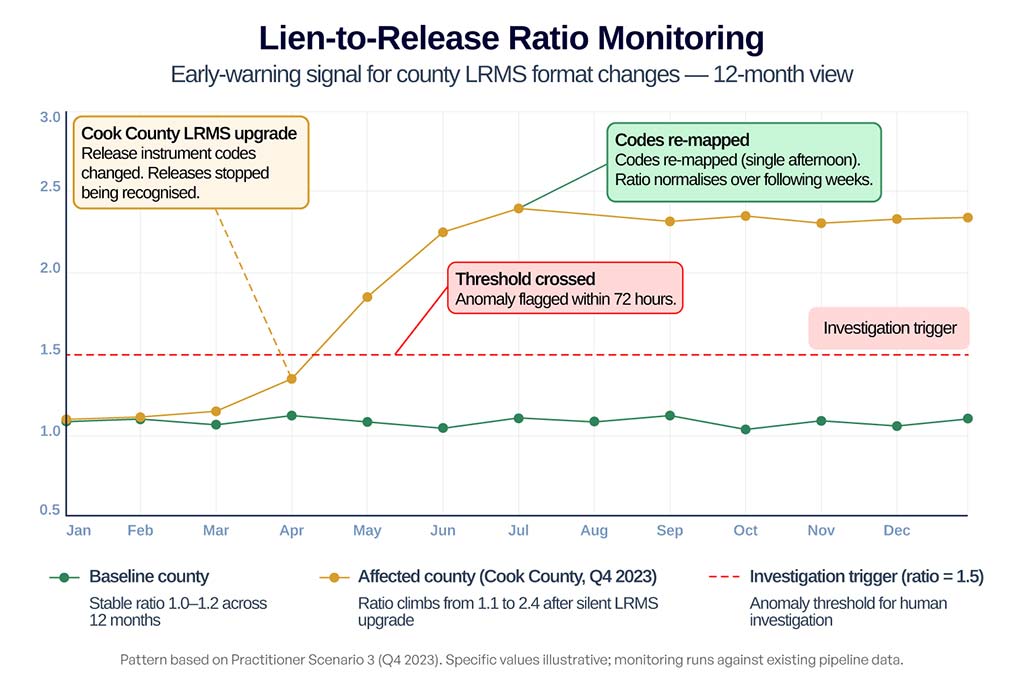
Practitioner Scenario 3: Cook County LRMS upgrade and phantom encumbrances (Q4 2023)
In Q4 2023, Cook County rolled out a phased LRMS upgrade that quietly changed several release instrument codes. Two property data platforms relying on generic IDP did not catch the change for over five weeks. During that window, release filings were ingested as unrecognized document types and silently dropped from the release index.
Mortgage releases stopped clearing in client products, generating phantom encumbrances across thousands of Cook County parcels. Hitech i2i’s lien-to-release ratio monitor flagged the anomaly within 72 hours of the first affected batch, the ratio climbed from a steady 1.1 baseline to 2.4 in under two weeks. Re-mapping the new codes took an afternoon once the anomaly was identified.
The FTC enforcement action against CoreLogic’s data delivery to ATTOM (then RealtyTrac) shows what happens at the extreme end of this failure mode. Systematic gaps in bulk county data, missing deed and mortgage records persisted undetected for years. No monitoring was in place to catch county-level format or coverage failures.
ATTOM CEO Rob Barber’s response to multi-sourcing data across providers acknowledged that a single extraction layer without monitoring cannot hold at pipeline scale.
The Solution: What Domain-Trained OCR for County Property Records Does Differently
Generic IDP reads characters. Domain-trained OCR for county property records reads instrument context.
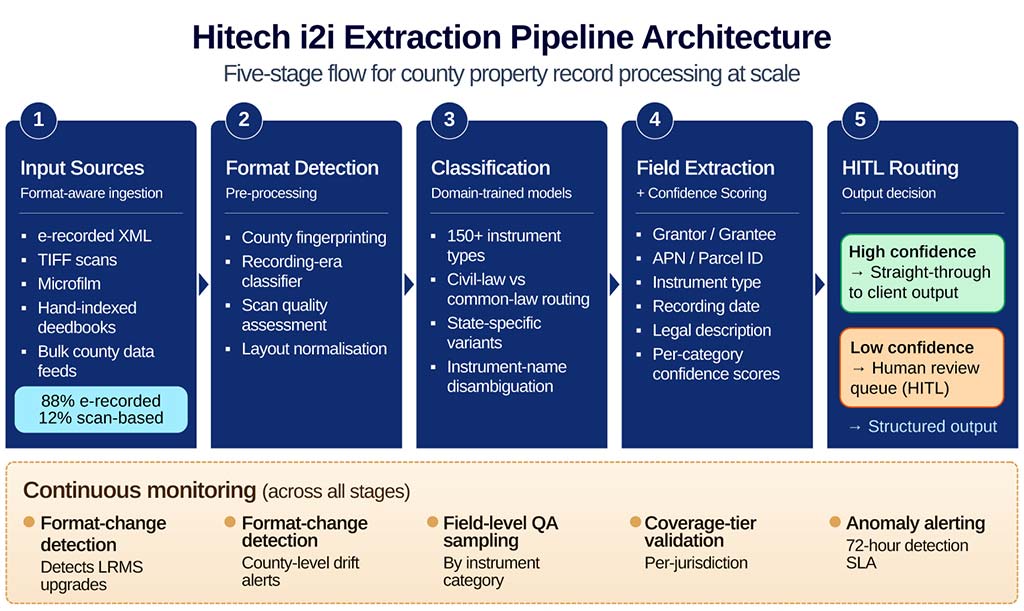
Generic IDP architecture (for comparison)
- Collapses stages 2–4 into a single document-level model.
- No civil-law routing. No instrument-category confidence scoring.
- No monitoring layer for county-level format changes.
Hitech i2i domain-trained architecture
- Each stage is specialised; classification precedes extraction.
- Civil-law and state-specific routing built into stage 3.
- Continuous monitoring catches drift before it reaches output.
The practical difference operates at four levels:
- Instrument vocabulary mapping: a domain-trained model knows that “materialman’s lien” in Texas is the functional equivalent of “mechanic’s lien” in Illinois, and routes both to the same output category.
- County-specific field layout memory: the model locates the grantor name field in the position that county’s forms have historically placed it, not where a generic model assumes based on invoice or contract training data.
- Instrument-category confidence scoring: a domain-trained pipeline flags low-confidence extractions by instrument type and routes them to human review before they reach your output.
- Format-change detection: by monitoring lien-to-release ratios at the county level, the platform catches LRMS upgrades and recording code changes before they propagate as field errors in your client data.
AI document classification pre-trained across 150+ real estate instrument types addresses all three failure layers such as instrument vocabulary, field layout, and indexing variation in a single pipeline. AI data extraction for property records applies confidence scoring at the instrument-category level, not just the document level. This is the architecture that sustains 99%+ field-level accuracy with HITL routing across 1,000+ county formats.
What we have learned on a scale
After processing 12+ million county property records across 1,000+ U.S. counties, the single most expensive failure pattern we have corrected for is silent misclassification, extractions that look right by composite confidence but route the wrong instrument type into your downstream products.
Field-level confidence scoring at the instrument-category level, paired with continuous lien-to-release ratio monitoring, was the architectural change that closed this gap. Everything else in our pipeline, format detection, county fingerprinting, HITL routing exists to keep that gap closed at scale.
– Snehal Joshi, Head of Data Solutions, Hitech i2iEfficiency Gains: What the Field-Level Accuracy Gap Costs in Practice
The gap between 70–80% and 99%+ field-level accuracy on county property records is not abstract. It has a direct operational cost on your pipeline at every scale:
- At 70% field-level accuracy, 3 in 10 fields are wrong. Every record requires human review or produces client-visible errors.
- At 80% field-level accuracy, 1 in 5 fields is wrong. You need a QA layer that costs more in headcount than the IDP tool saves.
- At 99%+ field-level accuracy with HITL routing, human review is reserved for genuinely ambiguous instruments — the exception, not the standard workflow.
The practitioner evidence is consistent across document types. In a real-world mortgage document pipeline processing 6,000 loans per month, off-the-shelf OCR services plateaued at 70–72% field-level accuracy.
Routing documents through domain-specific extraction paths pushed accuracy to 96% and cut processing time from two days to thirty minutes. Your county property record pipeline presents the same structural challenge, but at a higher degree of format variation across 3,000+ jurisdictions.
Hyland, one of the largest enterprise content management vendors, publishes that most IDP solutions carry an accuracy range of 80–99%. The lower end applies precisely when documents are complex and variable. County property records consistently sit at the lower end for generic tools and at the upper end for domain-trained platforms.
Domain-trained IDP with purpose-built pre-processing reduces re-keying time on pre-1950 county property records by 40–60% compared to generic OCR. The condition; the model must be trained on the specific handwriting styles, ink degradation patterns, and physical formats those records present (operational experience, 1,000+ U.S. county formats, see Methodology Note).
Best Practices: 4 Steps for Data Platforms Processing County Property Records at Scale
1. Run the Hard-County Test before any OCR vendor commitment
Request a sample run on your most difficult county property records, not on the vendor’s benchmark documents. Include:
- Mechanic’s liens from Texas (materialman’s lien instrument name).
- Foreclosure instruments from Florida (judicial) and California (non-judicial).
- Heirship affidavits from rural Texas counties.
- Pre-1950 deeds from any manual-access county.
Any domain-trained platform should return instrument-category field-level accuracy results on your actual county data within 48 hours. Generic IDP vendors typically cannot carry their models without county-specific training data.
2. Demand field-level accuracy by instrument category, not composite scores
A composite field-level score masks instrument-category performance. Request specifically:
- Field-level accuracy on lien instruments in Texas and Florida.
- Field-level accuracy on foreclosure sequences in judicial and non-judicial states.
- Field-level accuracy on county property records recorded before 1980.
Any vendor leading with character-level accuracy figures is not giving you the metric that matters for your production pipeline decisions.
3. Build county coverage tiers before adding new jurisdictions
Track coverage quality by instrument category within each county, not as a binary in-coverage flag. Tier your county property record coverage into:
- Validated: all core instrument categories tested and confirmed at field level.
- Partial: deed coverage confirmed, lien and specialty instruments pending validation.
- Best-effort: new jurisdiction, benchmark coverage only.
Validate the instrument taxonomy of any new county before going live. Discovery via client reports is the most expensive validation method you can use.
4. Monitor lien-to-release ratios as a format-change early-warning system
For every lien category, compare lien recording volume to release recording volume over a rolling 90-day window by county. A county where lien recordings climb relative to releases is almost certainly capturing liens but missing corresponding releases typically because the county upgraded its LRMS and release instrument codes changed.
This monitoring query runs against your existing pipeline data and costs nothing to implement. It catches county property record format changes before they become client-visible field errors.
Future Outlook: Where OCR for County Property Records Is Heading
The next generation of county property record processing is moving beyond character recognition into semantic instrument understanding:
- Large language models (LLMs) fine-tuned on property record text are beginning to classify a Deed-in-Lieu of Foreclosure by reading instrument language as legal context, not field position.
- Confidence scoring is becoming instrument-category-specific rather than document-level, enabling more precise human review routing on the instruments where field-level accuracy is historically lowest.
- Each new jurisdiction joining an eRecording network directly improves structured input quality for downstream extraction, reducing the scan-based extraction burden that produces the lowest field-level accuracy outcomes.
Platforms building domain-trained extraction pipelines now will absorb those format improvements automatically. Platforms dependent on generic IDP tools will continue requiring manual remediation for each new jurisdiction and each LRMS format change that no generic model anticipated.
How Hitech i2i Addresses Field-Level Accuracy Across 3,000+ County Property Record Formats
Hitech i2i is a Real Estate Document Intelligence Platform built specifically for the county property record processing challenges described in this article. The platform is pre-trained on 150+ real estate document types across 1,000+ U.S. county formats, covering instrument naming variation, county-specific field layouts, and recording-era format differences that generic IDP tools have never encountered in training.
| Documented Outcome | Detail & Source |
|---|---|
| 99%+ field-level accuracy with HITL routing | Across core instrument types such as deeds, liens, mortgage assignments, and foreclosure instruments, with confidence scoring at the instrument-category level. |
| 60–70% reduction in processing costs | Compared to generic IDP solutions and the QA headcount needed to address field-level accuracy gaps. AI-driven property document processing delivers greater efficiency and accuracy across 1,000+ counties. |
| 4–24 hour turnaround | On structured, commitment-ready output across residential, commercial, and specialty instrument types. |
| 80% reduction in manual work | For a leading U.S. real estate intelligence platform digitizing 20,000+ historical documents with irregular layouts and multi-decade scan quality variation. |
Trusted by ATTOM Data, The Warren Group, CRS Data, and Yardi for property data aggregation at scale.
Conclusion
The field-level accuracy gap between generic IDP and domain-trained extraction on county property records is not 2 percentage points. The published evidence shows it is 20–30 percentage points, the difference between 70–80% for generic tools and 99%+ with HITL routing for domain-trained pipelines. At your pipeline’s scale, that gap means hundreds of unusable fields per day, a QA headcount that offsets the automation investment, and client-visible errors that accumulate before anyone identifies the source.
Your specific next step before your next vendor evaluation or county coverage expansion: demand field-level accuracy results by instrument category on your own county data, not composite scores on vendor benchmark documents. That single test will reveal more about production performance than any benchmark a generic IDP vendor provides.
As eRecording adoption continues and AI moves toward semantic instrument understanding, the gap between domain-trained and generic pipelines will widen rather than narrow. Platforms investing in county-specific extraction infrastructure now are building a data quality advantage that compounds with every county added to coverage.
Request a free sample run on your own county property record data.
Get field-level accuracy results by instrument category within 48 hours. No commitment required.
Request a free sample run »Frequently Asked Questions About OCR for County Property Records
Generic IDP is trained on structured documents with consistent layouts and stable vocabularies, such as invoices, forms, and contracts. County property records are the opposite. The same instrument type arrives under different names across states, in different field positions across county form versions, and in physical formats ranging from e-recorded XML to hand-indexed 1940s deed books.
Generic IDP tools plateau at 70–80% field-level accuracy on complex variable documents, the category your county property records fall into. One in four to one in five fields is wrong before any county-specific failure mode is even considered.
Field-level accuracy measures whether a complete data field such as grantor name, instrument type, APN, recording date, is extracted correctly in its entirety. A single misread character in a parcel identifier or instrument type code is a field-level failure, regardless of how many other characters were correct.
Character-level accuracy is the metric generic OCR vendors lead with because it produces the highest numbers. It is not the metric that determines whether your extracted county property record data is usable without human review.
In fully digitized counties with structured e-recorded documents, domain-trained extraction sustains 99%+ field-level accuracy with HITL routing on core instrument categories. In semi-digitized counties, field-level accuracy on pre-1980 instruments falls without county-specific pre-processing and layout models.
In manual counties with deed books and microfilm, generic IDP returns fragmented or garbled output on a significant proportion of records regardless of scan quality. The recording era is as important as the county tier, a 1940s deed from a fully digitized county still requires historical layout models that generic IDP does not carry.
The highest-risk categories for field-level failures in your county property record extraction are:
- Mechanic’s and construction liens: five to six different instrument names across states.
- Foreclosure instruments: judicial and non-judicial sequences produce entirely different instrument types.
- Sheriff’s and Commissioner’s deeds: different names in nearly every state.
- Texas heirship affidavits: transfer ownership without a deed, missed entirely by deed-based ownership tracking.
- Lis pendens notices: frequently misclassified as liens despite a fundamentally different legal effect.
A misclassified lien or missed heirship affidavit produces field errors that are expensive to remediate once they reach your client’s data product.
Test on your hardest county property records, not on vendor benchmark documents. Demand field-level accuracy results by instrument category, not composite scores or character accuracy figures. Ask specifically about civil-law state coverage (Louisiana), Texas lien instrument variants, pre-1950 historical records, and the vendor’s process for detecting county LRMS format changes.
A domain-trained vendor should return field-level accuracy results by instrument category on your own county data within 48 hours. Any vendor unable to demonstrate performance on your specific document mix before commitment is not ready for your production pipeline.
Disclosure
This article is published by Hitech i2i. Where independent benchmarks are cited, those sources are linked inline. Where figures derive from Hitech i2i’s operational experience, they are labelled in the Methodology Note below. Outcomes attributed to Hitech i2i clients are documented in linked customer stories. Practitioner scenarios are based on documented failure patterns observed across Hitech i2i’s county coverage and are labelled as Tier 2 operational experience throughout.
Methodology Note
Field-level accuracy figures attributed to operational experience in this article are derived from work across 1,000+ U.S. county formats and reviewed against publicly available industry data from:
- ALTA: ALTA TitleNews Magazine (June 2021)
- PRIA: PRIA Industry Resources
- Nanonets: Guide to Intelligent Document Processing
- Lido.app: OCR Accuracy Benchmarks
- IDP Software: 2026 IDP Accuracy Analysis
- ACM Conference: ACM Research on Document Processing
- Hyland: How to Choose the Right IDP Solution
- HousingWire: FTC Sanctions Against CoreLogic
Practitioner scenarios are based on documented failure patterns observed across Hitech i2i’s county coverage and are labelled as Tier 2 operational experience. The county property records row in the field-level accuracy comparison table is an extrapolation from the complex variable documents benchmark range; no published independent benchmark for generic IDP field-level accuracy specifically on county property records currently exists. All other rows cite independent published sources with URLs.
These figures are planning references intended to supplement, not replace, the operational knowledge of experienced data engineers and operations leaders.
← Back to Blog
